
Cómo crear inteligencia artificial

Pueden literalmente extraer sueños y otras cosas increíbles además de los ya conocidos chats que superan el test de Turing, es decir que pueden hacerse pasar por humanos, pero la realidad es que no lo son y ese es un aspecto muy importante, como veremos en este artículo, no hay magia, hay algoritmos, hay estadística y muchas matemáticas en general.
- Pablo García Moreno - METAS MARKETING DIGITAL

Clarificando términos
Inteligencia Artificial - Machine learning - Deep learning.
La intención de este artículo es dar una primera aproximación a la inteligencia artificial, una visión conceptual y rápida para intentar comprender un poco de este mundo de la mejor manera que creemos en Metas que se puede comprender algo, haciendo. Sin entrar en disquisiciones filosóficas, la palabra inteligencia artificial (IA) acuñada en los años 50 es un concepto muy vago para muchos, nosotros incluidos. Sabemos que tiene que ver con máquinas realizando tareas intelectuales de los humanos, que sirven para reconocer y tratar las imágenes o la voz, que pueden literalmente extraer sueños y otras cosas increíbles además de los ya conocidos chats que superan el test de Turing, es decir que pueden hacerse pasar por humanos, pero la realidad es que no los son y ese es un aspecto muy importante, como veremos en este artículo, no hay magia, hay algoritmos, hay estadística y muchas matemáticas en general. Las neuronas de la IA en nuestra opinión solo en pocos aspectos tienen que ver con las biológicas, así que de momento sentimos pincharte el globo pero el robot de Terminator aún no te lo podrás comprar.

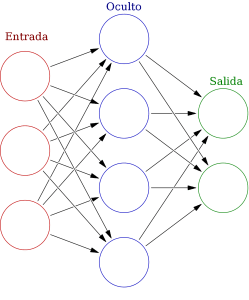
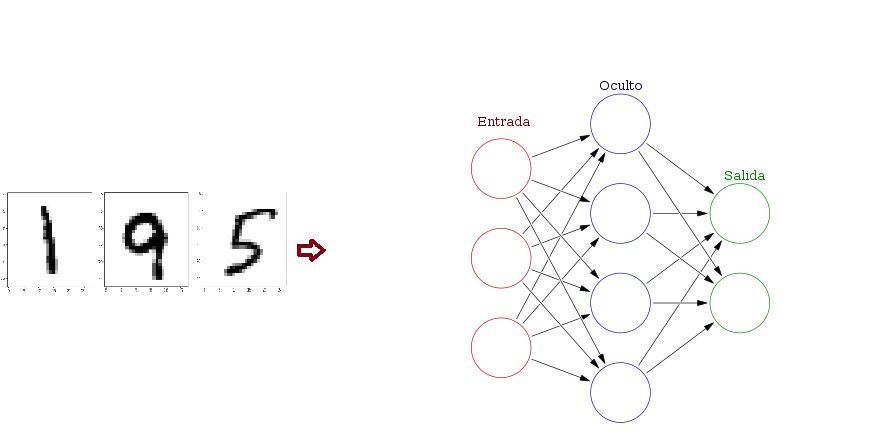
No hará falta que sepas programar, todo el código que usemos lo explicaremos en lenguaje natural para que se entienda. Iremos introduciendo conceptos poco a poco y nos apoyaremos en un ejemplo archiconocido en IA, tomaremos un montón de dibujos escritos a mano con los dígitos del 0 al 9 (como los de la figura superior) y con IA crearemos un programa que intente clasificarlos él solo, es decir del mismo modo que una persona puede ver la figura superior y decir que esos dibujos se corresponde con los números uno, nueve y cinco, nosotros crearemos un programa que al mostrarle esos mismos dibujos y muchos otros nos diga qué números cree que son. Para ser mas precisos, podemos decir que nuestro programa aprenderá a clasificar automáticamente los números, este tipo de programas que como veremos mediante entrenamiento aprenden automáticamente sin que el programador le indique «por donde tiene que tirar», pertenecen a una rama de la IA llamada Machine Learning (ML). El aprendizaje en el ML puede ser supervisado, es decir que los datos con los que se entrenará el programa para «aprender» incluyen la solución o puede ser no supervisado y en ese caso nuestro programa deberá entrenar sin tener soluciones, lo que técnicamente se conoce como búscate la vida. En nuestro ejemplo de los dígitos que luego veremos, usaremos un aprendizaje supervisado, es decir le daremos las soluciones correctas para que aprenda. Incluso podemos ser mas concretos aún, en nuestro ejemplo de ML supervisado, usaremos específicamente el llamado Deep Learning (DL) o aprendizaje profundo, un área del ML basado en modelos con múltiples capas interconectadas como puede apreciarse en la siguiente figura, donde una capa son los circulos rojos (llamada capa de entrada), otras los azules (llamada capa oculta) y otras los verdes (llamada capa de salida) de modo que como luego veremos, los datos se irán procesando por las diferentes capas. Observando esta figura en cierto modo se puede apreciar un aire al modo en que está interconectadas las neuronas en nuestro cerebro y por eso es habitual hablar de redes neuronales artificiales donde los nodos o círculos son llamados neuronas.
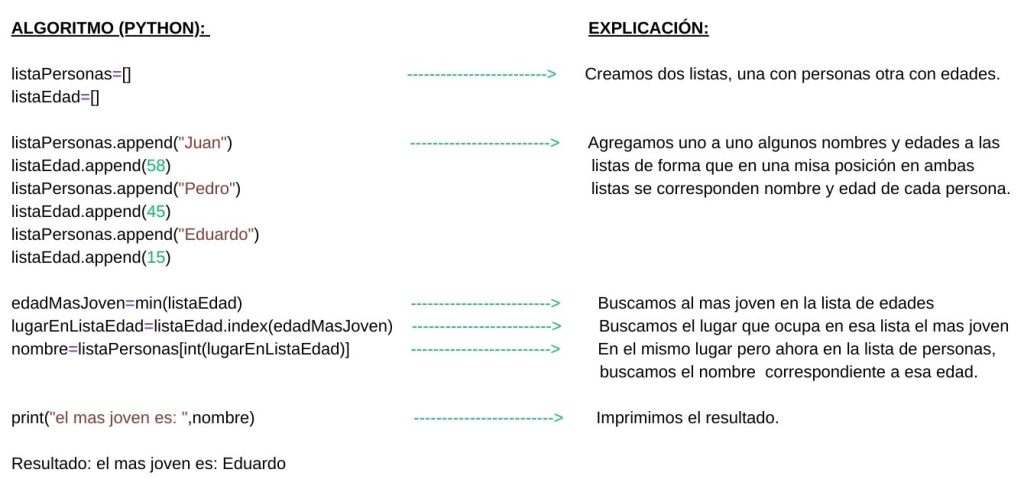
Como «algoritmo» es un término que mencionaremos muchas veces, antes de empezar intentaremos explicar rápidamente su significado puesto que es algo muy fácil de entender, de modo intuitivo podemos definir perfectamente un algoritmo como una serie de pasos para realizar una tarea o solucionar un problema. Cuando seguimos una recta de cocina como podría ser por ejemplo «agregar 2 patatas, luego zanahoria, a continuación agua, luego revolver» en cierta forma estamos realizando un algoritmo, en cada paso agregamos un nuevo ingrediente o realizamos algún proceso, todo para conseguir un fin último, una buena comida o tomar un par de Almax. Cuando programamos estamos empleando permanentemente toda clase de algoritmos, por ejemplo imaginemos que tenemos que resolver un problema, necesitamos saber quien es la persona mas joven de una lista y para solucionarlo nos piden que creemos un algoritmo en el lenguaje de programación Python, de modo que se nos ocurre el algoritmo que hemos puesto en la siguiente figura, éste algoritmo irá realizando una serie de pasos o dicho de otro modo ejecutando una serie de instrucciones una a una para lograr encontrar a la persona mas joven de la lista. Como hemos dicho no hace falta entender el código porque podemos entender conceptualmente que es lo que hace cada instrucción con las explicaciones puestas a la derecha de cada una, sin necesidad de saber programar ni de comprender Python. En nuestro algoritmo inventado, hemos empezado creando dos listas, una con nombres y otra con edades para que a continuación y mediante una serie de instrucciones se encuentre e imprima el nombre de la personas mas joven:
Siendo realistas para un problema tan simple como encontrar la persona mas joven de una lista con solo tres nombres como la nuestra, la verdad no hacía falta hacer ningún algoritmo porque cualquier persona lo podría solucionar mirando simplemente la lista un segundo, pero imaginemos que fuera el caso de una empresa con una lista de clientes con miles de nombres, nuestro algoritmo sería capaz, incluso en un ordenador convencional de obtener una respuesta casi instantánea. Este detalle de la velocidad es algo importante a mencionar en el tema que nos ocupa, porque aunque la IA no sea algo nuevo, si que es verdad que gran parte de su gran avance actual ha sido propiciado por las grandes mejoras que ha habido en la capacidad de procesamiento, aunque por supuesto no solo, también han sido fundamentales los avances en algoritmia, en generación de datos, en el hardware de almacenamiento para gestionar eficazmente bases de datos NoSQL, en el Cloud Computing y en framewoks de código abierto como Keras entre muchas otras cosas. No te preocupes si no entiendes de que hablamos, no es mas que información general, la intención de este articulo es que nada, ni siquiera las partes codificadas sean un escollo para que puedas hacerte una idea del tema, todo el código que pongamos será explicado en un lenguaje accesible para quienes no sepan programar y aún así puedan comprenderlo todo. No obstante si la parte codificada es justo la que te interesa y quieres reproducirla por tu cuenta, tendrás que tener instalado Python; aunque hay que tener claro que la IA no es algo privativo de Python, aun siendo el mas popular en estos temas por su gran cantidad de librerías y herramientas disponibles no es el único, también se usan entre otros Java, C++ y R. Si estás aprendiendo a programar, te recomendamos trabajar como entorno de desarrollo con Jupyter (notebook o lab) porque aunque no llega a ser un IDE completo, es mas que suficiente para realizar los ejemplos que veremos, además permite trabajar en bloques y posee un entorno de ploteo interactivo muy útil.
reconociendo dígitos
Mnist - Red Neuronal - Normalización - Entrenamiento
Como ya hemos dicho partiremos de un montón de imágenes de dígitos hechos a mano para clasificarlos, ese conjunto de datos de partida que usaremos ya existe y se conoce como MNIST, contiene un conjunto de 60000 imágenes de dígitos llamado x_train para entrenar el modelo (ya veremos mas adelante que es eso) mas un conjunto de 10000 imágenes adicionales llamado x_test para testearlo, en la primera figura de este artículo se ven tres de estas imágenes MNIST. Para realizar la clasificación construiremos una red neuronal y para ello usaremos una librería en Python llamada Keras, una librería es un conjunto de archivos de código para facilitar la programación, es decir del mismo modo que para construir una casa no construimos las puertas y ventanas desde cero sino que vamos a un almacén de construcción y las compramos hechas sin importarnos en lo mas mínimo como se han fabricado, las librerías contienen enorme cantidad de cosas ya hechas por otros, cosas como funciones y métodos para facilitarnos la vida. Para entenderlo con un ejemplo, imaginemos que tenemos que encontrar el camino mas corto entre dos puntos en una red, podemos crear un algoritmo con un montón de instrucciones que lo resuelvan, pero un camino mas práctico es usar un método de la librería networkx llamado shortest_path ya creado para este propósito, de modo que usando ese método en una instrucción de nuestro código resolveremos el problema sin siquiera preocuparnos de cómo shortest_path nos ha dado el resultado, es decir que algoritmo ha usado internamente para darnos el resultado correcto. La librería Keras entre otras cosas nos permitirá implementar nuestra red neuronal de una forma fácil de entender y es una librería que se apoya a su vez en otra muy potente llamada TensorFlow, dicho de una manera mas técnica Keras usará como backend TensorFlow. De modo que para empezar con nuestro código, en primer lugar traeremos hacia nuestro programa (eso se llama importar) dos cosas, la librería Keras y las imágenes de dígitos MNIST, así podremos tener ambas disponibles para usarlas en nuestro código. Como ya hemos dicho no será necesario entender las instrucciones en código porque en todo momento pondremos comentarios detallados acompañando al código para que quienes no sepan programar puedan igualmente comprender que es lo que se está haciendo. Los comentarios no son mas que acotaciones que se ponen habitualmente en el código con el fin de ayudar a clarificar, algo parecido a cuando uno pone anotaciones en los márgenes de un documento que está escribiendo; en Python los comentarios empiezan con el símbolo # y los podremos ver en la siguiente figura en color azul, Los comentarios no formarán parte del ejecutable del programa, dicho de otra manera serán ignorados por el intérprete de Python por lo que nos permitirán entender que hacen las instrucciones sin afectar en nada al funcionamiento de nuestro programa.

No lo habíamos mencionado aún, pero cada imagen MNIST de cualquiera de los dígitos a mano, tiene asociada una etiqueta, si nos ayuda podemos pensar en etiquetas como las de los precios que cuelgan de los artículos en una tienda, nuestras imágenes tienen una etiqueta «colgando» con el valor correcto de la propia imagen, es decir puede suceder por ejemplo que viendo la imagen de un seis manuscrito tengamos dudas de si realmente se trata de un seis o puede que sea un ocho mal dibujado, para salir de dudas, podremos mirar la etiqueta de la imagen y saldremos de dudas viendo que efectivamente la etiqueta dice 6. Todas estas etiquetas serán en definitiva el resultado correcto que debería dar el algoritmo que estamos construyendo para cada imagen, de hecho efectivamente esas etiquetas son las que usará el algoritmo en su entrenamiento de aprendizaje, para saber a medida que entrena si esta acertando bien o por el contrario es un desastre y no pega una. Podemos pensar en el entrenamiento de nuestro algoritmo como si fuera un baloncestista que entrena a base de tirar pelotas al aro, cuando falla el tiro, la siguiente vez corrige un poco el movimiento para así intentar tener cada vez mas aciertos, esos aciertos al aro serán el equivalente en nuestro entrenamiento a acertar el valor de nuestras etiquetas. Veamos un poco mas esto de las etiquetas con un ejemplo, vamos a escoger de la enorme cantidad de imágenes con números que tenemos guardadas en una especie de archivador la que está en la posición 45 y mediante una instrucción imprimamos su etiqueta como se ve en la figura siguiente:

La etiqueta de la imagen 45 como vemos en la figura anterior nos indica que corresponde a un número 9, pero podemos imprimirla para corroborar que efectivamente lo que dice su etiqueta es cierto:

Puede verse en la figura anterior que una vez impresa sin duda es un número 9 y que es correcto lo que dice su etiqueta. Las etiquetas (label en inglés) de las imágenes, o sea el resultado correcto es lo que intentaremos predecir con nuestro algoritmo, Como luego veremos, las imágenes como la anterior serán las que nuestro modelo tendrá como entradas, en realidad si prestamos atención a la figura anterior, veremos que las imágenes tienen números en los costados, esto es porque en realidad son matrices de 28 x 28 píxeles, una matriz es como una hoja cuadriculada sobre la que se ha dibujado el número y donde cada cuadradito es lo que se llama un píxel, este pixel será negro si el trazo del número pasa por él, gris si pasa pero no muy fuerte y blanco si no pasa, la imagen estará formada por todo el conjunto de pixeles que serán 28 x 28 o sea un total de 784 píxeles. Este tipo de estructura básica de datos que usaremos es lo que se conoce como tensor. ¿Cómo nos indica un pixel que es mas o menos negro? pues con valores, si vale cero (el mínimo) es que es blanco, si vale 255 (el máximo) es que es negro y cualquier número en medio significará que el pixel es un gris mas o menos fuerte. Ahora que hemos entendido como están formadas las imágenes, viene la gran decepción, así como están no nos van a servir. Llegados a este punto es importante entender que los datos de entrada, es decir los conjuntos de imágenes x_train y x_test, siempre deben adecuarse para que nuestro algoritmo los pueda procesar, es decir no podemos coger imágenes de números giradas, o en diferentes tamaños y formatos sin mas, sino que todo deberá estar armonizado con unas proporciones similares, centrado, bien orientado, etc. en definitiva debemos transformar las imágenes para que nuestro algoritmo pueda trabajar con ellas sin problemas, ese proceso de preparar los datos se conoce como normalización y es lo que haremos a continuación con las instrucciones que podemos ver en la siguiente figura. En la primera parte lo que haremos será escalar los valores de los 784 píxeles que tiene cada matriz, es decir haremos que en lugar de moverse con valores que están en un rango entre 0 y 255 como hemos visto antes, se muevan con valores entre 0 y 1, para hacer esto es necesario primero que pasemos todos esos valores de los píxeles que son enteros a reales, eso es lo que hace la primera instrucción al pasar los números al formato float32. En la segunda parte de la figura siguiente, mediante dos instrucciones transformaremos los dos conjuntos de imágenes que usaremos para que los valores de píxeles de cada imagen pasen de estar de una matriz de 28 x 28, a estar todos en una sola tira larga de 784 valores, porque ese es el formato que acepta como entrada una red como la que estamos creando, para entenderlo con un ejemplo, es como si la entrada de nuestra red fuera un agujero muy pequeño y quisiéramos meterle un gran pañuelo de lana (la matriz) la solución para conseguirlo sería tirar primero de un hilo en una punta del pañuelo hasta quedarnos con exactamente el mismo pañuelo pero hecho un solo hilo largo, de este modo podrá pasar por el agujero. este tipo de estructura como la del hilo largo se conoce como vector y lo veremos a continuación.

Las etiquetas con los valores correctos de las imágenes, que como habíamos visto consistían en un valor entre 0 y 9, también tendremos que, aunque suene raro transformarlas en un vector equivalente, ahora veremos cómo se hace, podemos pensar en un vector como una larga fila de cajitas de madera todas unidas donde podemos guardar cosas, en nuestro caso lo que vamos a conseguir es tener un vector de 10 cajitas (una por cada dígito del cero al nueve) y en cada una de esas cajitas guardaremos un valor que será cero o uno. Si por ejemplo tenemos una etiqueta con el número 9, esta etiqueta será transformada en un vector donde cada una de sus cajitas desde la primera hasta la octava, tendrán dentro un cero pero la novena tendrá un uno. Es decir nuestro vector para la etiqueta nueve será algo así: 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 donde el 1 en la posición 9 indica que ese vector corresponde a una etiqueta con un valor nueve, si la etiqueta fuera un 2 su vector sería : 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 (recordar que la primera cajita es el cero). Para este proceso de transformar la etiqueta en vector, usaremos un método que tiene Keras llamado to_categorical.

Llegados a este punto donde ya tenemos todos los datos preparados, entendamos primero un poco que es lo que vamos a hacer a continuación. Como ya hemos dicho nuestras imágenes de entrada con los números manuscritos tienen valores en sus píxeles que variarán según los pixeles sean negros grises o blancos, estos valores o variables se conocen como features o características de entrada, por otro lado ya hemos visto que tenemos etiquetas con los resultados correctos de cada imagen. Lo siguiente que haremos será crear nuestro modelo, ese modelo, será en definitiva el encargado de relacionar las features de entrada con las etiquetas. No es necesario complicarse demasiado para entender que es un modelo, será mas que suficiente con manejar la idea pero igualmente intentaremos explicarlo de un modo comprensible, el modelo es en realidad una representación conceptual que podemos definir como el conjunto de todas las funciones matemáticas que se aplicarán a los datos de entrada para producir la salida final, la red neuronal que construiremos mediante instrucciones en Python será en realidad la implementación «real» de dicho modelo, dicho todo lo anterior en cristiano el modelo serán los planos de la casa y la red neuronal que crearemos con instrucciones en Python será la casa. Nuestra red neuronal una vez creada tendrá solo tres capas (las hay con muchísimas mas) con sus respectivas neuronas interconectadas, algo muy parecido a la siguiente figura donde se puede apreciar mirando las flechas como todas las neuronas de una capa están conectadas con todas las neuronas de la capa anterior, por este motivo nuestra red pertenecerá a un tipo de redes llamadas densamente conectadas. La idea visual es simple, nuestra red recibirá los datos de las imágenes (en un vector de 784 valores tal como hemos visto antes) y sobre esos valores se irán haciendo cálculos a medida que van pasando por las capas, tal como se sugiere en la figura siguiente de una red, nuestra red funcionará igual, solo que tendrá un número diferente de neuronas.
Aunque luego lo explicaremos mejor, necesitaremos saber que del mismo modo que un televisor tiene unos valores que nos permiten ajustarlo (brillo, color, etc.) de forma parecida nuestra red también tendrá unos valores que permitirán ajustar su propio funcionamiento, uno de ellos es el llamado peso, a grandes rasgos las neuronas de nuestra red tienen asignados pesos que indican algo así como la «fuerza» de cada una de las conexiones entre neuronas. El mecanismo que usará nuestra red es sencillo, la primera capa, la de entrada recibirá en cada una de sus neuronas los datos (las 784 features) de una imagen y hará cálculos sobre ellos, cada una de estas neuronas pasará su resultado a las neuronas de la siguiente capa llamada capa oculta, a su vez cada una de las neuronas de la capa oculta hará nuevamente cálculos con los resultados recibidos de la capa anterior y pasarán sus propios resultados a las neuronas de la última capa llamada capa de salida, las neuronas de esta última capa de salida a su vez también realizará cálculos propios con los datos recibidos y para terminar mediante una función especial llamada softmax nuestra red presentará los resultados finales obtenidos en forma de probabilidad, es decir la red para cada imagen de entrada, nos dirá finalmente cual es su predicción, algo así como «este número parece un 3 con un 90% de probabilidad». Este proceso anterior de pasar las imágenes capa por capa se realizará una y otra vez hasta usar todas las imágenes, pero el detalle es que en cada repetición la red irá realizando pequeños ajustes en algunos de sus valores como los pesos para ir mejorando sus resultados, todo este mecanismo repetitivo es lo que se conoce como entrenamiento. ¿Pero cómo consigue saber la red cómo debe autoajustarse para conseguir mejores predicciones? pues verificando que los cambios que introduce en sus valores en cada repetición con nuevas imágenes vayan en la dirección de que sus predicciones acierten cada vez mas o lo que es lo mismo haciendo disminuir el error en cada una de sus nuevas predicciones, no debemos olvidar que los datos de entrada en nuestra red tienen etiquetas con los resultados correctos por lo que la red puede saber si ha cometido o no un error. Esta medida de error que se deberá ir reduciendo mediante sucesivos ajustes en los valores de la red, es lo que se conoce como «loss». Habiendo comprendido grosso modo lo anterior, ya podemos pasar a la práctica y crear nuestra primera red neuronal, para ello, como se ve en la primera parte de la siguiente figura en la primera instrucción importaremos la clase sequential de Keras que nos permitirá crear una red neuronal densamente conectada de un modo muy fácil. En la segunda parte de la siguiente figura tenemos dos instrucciones con las que crearemos dos capas en nuestra red, la primera instrucción creará una primera capa de 10 neuronas, esta capa usará una función de activación sigmoid que es otra función de activación como softmax que ya hemos visto aunque diferente, sigmoid permite que los valores muy extremos no se eliminen, además indicaremos en la misma instrucción que esta capa recibirá los datos de entrada, es decir los vectores con las 784 features de cada imagen. La segunda instrucción creará una segunda capa de 10 neuronas con la función de activación softmax. Aquí viene una primera puntualización, como puede apreciarse en la figura anterior con el dibujo de nuestra red, se suponía que nuestra red iba a tener tres capas, entrada, oculta y salida, pero por lo que vemos en las instrucciones de la figura siguiente lo que estamos creando al parecer es una red con solo dos capas, esto es porque en realidad lo que ha sucedido es que la primera instrucción ha creado dos capas y la segunda una, o sea que en total si se habrán creado tres capas. Si observamos la primera instrucción veremos que se crea una capa de 10 neuronas con la función sigmod y en la misma instrucción con input_shape(784,) se indica que además tendremos una capa de entrada de 784 neuronas, luego la segunda instrucción creará otra capa, es decir que en realidad sí habrán tres capas. Aquí haremos un pequeño inciso aclaratorio, pero no te preocupes si no comprendes del todo la siguiente explicación porque no es imprescindible para seguir adelante. La capa de entrada, con los datos de entrada en una red densamente conectada como la nuestra, tiene que tener el mismo numero de neuronas que features tiene cada vector de entrada (en nuestro caso 784) poniendo un símil, si se va a correr una carrera con 784 coches la parrilla de salida deberá tener 784 espacios para esos coches, por eso la primera capa deberá tener 784 neuronas, pero siendo precisos y siguiendo la documentación oficial de Keras, la clase input no crea en realidad una capa de entrada en la red de 784 «neuronas», sino que con el vector de 784 features pasado como parámetro y mediante una operación de formato, lo que se crea es una capa de entrada subyacente que funciona «como» si fuera la capa de entrada aunque no usa neuronas, en esta capa se conecta cada feature directamente con cada una de las neuronas de la siguiente capa (la oculta). Es decir aunque no seamos muy exactos con la realidad, a efectos prácticos podemos considerar igualmente que Keras transforma nuestro vector de entrada en una primera capa de entrada con 784 neuronas, de este modo nuestra red tendría al igual que el dibujo de la figura anterior tres capas, la de entrada con 784 neuronas, la oculta con 10 neuronas y la de salida con 10 neuronas.

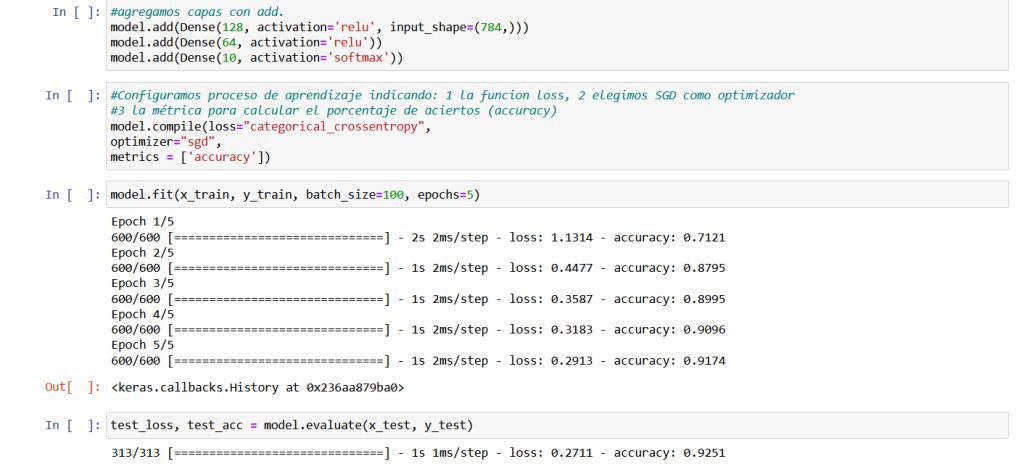
Ahora como puede apreciarse en la siguiente figura configuraremos los parámetros del proceso de aprendizaje y los explicaremos brevemente, uno de ellos es la función loss que ya hemos explicado en que consiste, otro de los parámetros es la accuracy que es la métrica que nos indicará cómo calcularemos el porcentaje de aciertos, concretamente la accuracy nos dará el porcentaje de aciertos sobre el total, por último también definiremos el algoritmo optimizador, para entender lo que hace el optimizador, recordaremos que las neuronas tienen pesos (indicativos de su «fuerza») estos pesos son los que se irán ajustando con el entrenamiento para minimizar el error en las predicciones y esto es exactamente lo que hará el optimizador, ajustar los pesos. En nuestro caso usaremos el optimizador SGD que se ayuda del cálculo de la primera derivada de la función loss para ajustar los pesos. Sin entrar en cuestiones matemáticas, pensemos en un símil para entender intuitivamente que es y como puede ayudarnos la derivada en este caso, imaginemos una persona que tiene que bajar una montaña en plena noche, seguramente como no sabrá hacia que lado ir y antes de ponerse a dar pasos, tanteará el terreno a su alrededor con el pie para ver la inclinación de la montaña, podrá determinar en que sentido la inclinación es hacia abajo y además según el grado de inclinación podrá ajustar el tamaño de sus pasos para no caer, desde el punto de vista matemático ese es el tipo de cálculo que nos permite una derivada, siendo mas exactos, podemos decir que el algoritmo SGD usando la derivada de la función loss permite conocer su pendiente y mediante una serie de cálculos ir ajustando los pesos de nuestra red para que la loss cada vez sea menor. Por no ser incompletos, es justo mencionar que las neuronas además de pesos tienen otro valor que se debe ajustar conocido como sesgo, pero a efectos de no complicar las explicaciones es algo que solo mencionaremos.

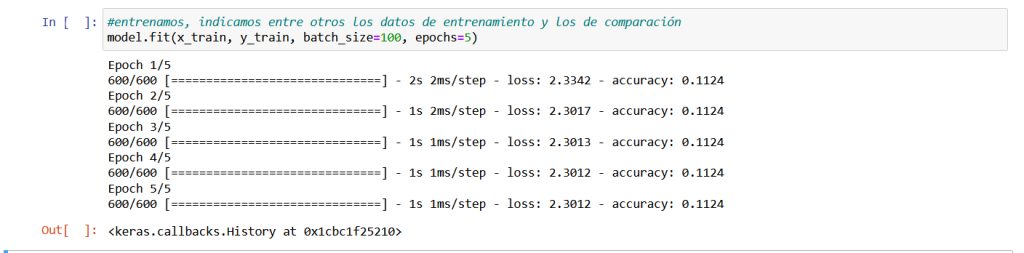
Ahora toca entrenar, para ello como se ve en la siguiente figura usaremos el método fit, al que le pasaremos el conjunto de imágenes (x_train) con las que entrenaremos el modelo. Nuestro modelo irá comparando sus resultados con los resultados correctos indicados en y_train (las etiquetas) para ir mejorando sus predicciones, esto lo hará tal como hemos comentado antes, calculando la loss y aplicando el optimizador para ajustar los pesos. Es decir en resumen fit cogerá los datos de entrenamiento, los pasará por la red neuronal, comparará resultados con y_train, calculará la loss y aplicará el optimizador para ajustar pesos, así varias veces. Con el parámetro epochs por su parte indicaremos el numero de veces que usaremos todos los datos en el proceso de aprendizaje, por motivos de eficiencia, las imágenes las iremos cogiendo de a 100 (eso es lo que indicaremos con el parámetro batch) para cada actualización de parámetros. Podremos ver también en la figura siguiente con la instrucción ya ejecutada que se nos irá mostrando el progreso del entrenamiento:
Una vez terminado el entrenamiento, veremos como se comporta nuestra red con datos de prueba nuevos (x_test e y_test). Como se ve en la figura siguiente usaremos el método evaluate para pasarle a nuestra red los datos de prueba y veremos la accuracy que obtiene o sea el porcentaje de clasificación correcto para estos nuevos datos.

Como podemos observar nos arroja un porcentaje bastante malo, solo un 11% de aciertos, nuestra red da un poco de lástima, pero podemos mejorarla. Llegados a este punto es muy importante mencionar un detalle importante, y es que de forma global, hay en nuestra red una gran cantidad de variables configurables, no nos referimos a los pesos que son ajustados durante el entrenamiento, sino a variables de la red en general tales como funciones matemáticas de activación, numero de neuronas en las capas y muchas otras cosas de las que solo hemos visto una pequeña parte, estas variables pueden ser configuradas para obtener mejores resultados dentro de unos tiempos de entrenamiento razonables, es decir puede que agregando neuronas y capas a lo loco obtengamos mejores resultados pero esto puede acarrear otro tipo de problemas incluido el del tiempo, de poco nos servirá mejorar un poco los resultados si a cambio hay que esperar dos años para obtenerlos. Esto de conseguir la configuración adecuada es algo que requiere un arte especial que solo da la práctica, sobre todo en redes mucho mas complejas que nuestro ejemplo didáctico. Como una muestra de lo que decimos probaremos unos cambios para intentar mejorar nuestra red, volveremos atrás hasta la parte de las instrucciones donde hemos agregado las capas a nuestra red y esta vez como se muestra en la siguiente figura agregaremos una capa mas o sea tendremos cuatro en vez de tres, además cambiaremos de optimizador, en vez de «sigmoid» utilizaremos otro llamado «relu» luego continuaremos como antes con el resto de instrucciones ya explicadas para evaluar los nuevos resultados:
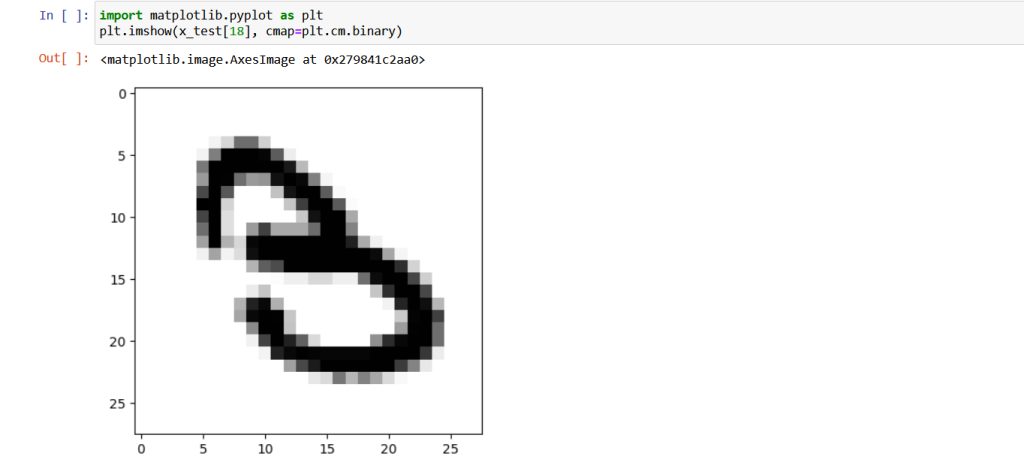
Como puede observarse en la figura anterior, con esos simples cambios el porcentaje de aciertos (accuracy) ahora ha mejorado pasando de un 11% a un 92% de aciertos. Hasta aquí hemos construido una red neuronal bastante eficiente. Ahora como tenemos tiempo (hemos tardado menos de dos años) vamos a afianzar conocimientos realizando una prueba manual a nuestro modelo para ver como se comporta, escogeremos una imagen del conjunto de imágenes de test, por ejemplo la imagen 18 que como podemos ver en la siguiente figura cuando la imprimimos se corresponde con un número 3, Si estás siguiendo el artículo reproduciendo el código al mismo tiempo ten en cuenta que puedes tener un error con la siguiente instrucción dado que al principio hemos normalizado las imágenes.
Como ya tenemos nuestra red entrenada, haremos una predicción como se muestra en la siguiente figura, ésta predicción nos devolverá un vector con las predicciones para todos los números del conjunto de imágenes x_test que le hemos pasado, conjunto que por supuesto incluye nuestro 3. Seguidamente a la predicción, importaremos la librería numpy, una librería que nos permitirá poder trabajar con vectores. A continuación en la siguiente instrucción usaremos la función argmax de numpy que nos permitirá ver en todo el conjunto de imágenes, cual cree nuestro algoritmo que es la número 18. Para terminar, la instrucción final imprimirá el array concreto con las probabilidades que nuestra red ha asignado a cada dígito del cero al nueve para la imagen 18:
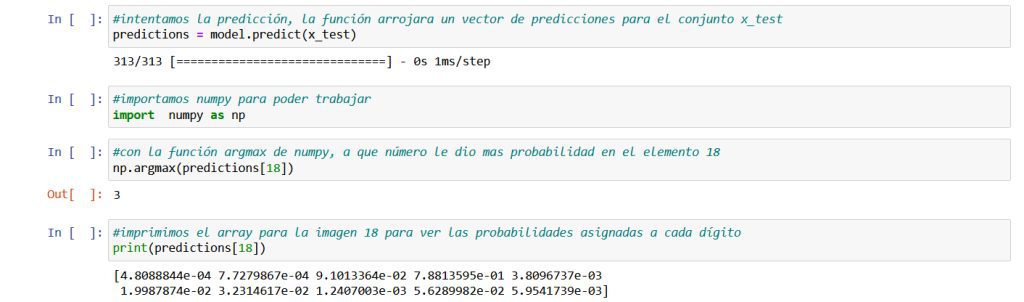
Como vemos en los resultados, nuestra red le ha dado a la imagen 18 una mayor probabilidad de que sea el número 3. Podemos observar en el vector resultado que es el numero 3 quien tiene una probabilidad mayor, 0,78813595 sobre 1 siendo el que le sigue el 2 con una probabilidad de solo 0,091013364.
Conclusiones
Nuevos términos - Investigación
Obviamente la intención de este artículo no era mas que dar una introducción muy superficial a las redes neuronales con uno de los ejemplos mas simples que hay sobre el tema y para aquellos que solo quieran hacerse una pequeña idea de los mecanismos que subyacen en redes de este tipo. No estaría mal a efectos de visualizar el funcionamiento de una red neuronal, que el lector complemente las ideas y conceptos que hemos visto experimentando con redes de un modo fácil y didáctico, para ello una opción muy buena es usar la herramienta online de Google playground. Por supuesto nos han quedado por mencionar muchas cosas que por lo menos para nosotros serían imposibles de abarcar en un artículo, nos hubiese gustado hablar brevemente del Perceptrón o neurona básica y génesis de muchos conceptos vistos allá por la década de los 50, también queríamos haber mencionado cuestiones como la regresión logística, la lineal, la clasificación multiclase, el overfitting, el concepto de forwardpropagation y backpropagation, comentar algunos parámetros e hiperparámetros como el learning rate o el momentum, mencionar las redes convolucionales, las recurrentes, las de base radial, el modelo transformer, las GANs entre muchas otras cosas, de modo que solo nos queda invitar al lector a que los siga investigando por su cuenta y a adentrarse en este mundo fascinante donde solo le hemos visto la punta al iceberg. Para terminar queremos agradecer el trabajo impecable de Jordi Torres, uno de los principales referentes en estos temas y en particular para este artículo junto con Inteligencia Artificial de Méndez, Tomás, Morales y Roque.